您现在的位置是:首页 > 创新技术
Cortex-M7,SiC MOSFET,逆变器,Cortex-M技术文章分享
智慧创新站
2025-04-16【创新技术】64人已围观
简介Cortex-M7内核的Cache是如何提升访问效率的?且看硬核实测大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形。上一篇文章《实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形(有预取)》里痞子衡抓取了...
大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形。
上一篇文章《实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形(有预取)》里痞子衡抓取了Cache关闭但Prefetch开启下的AHB读访问对应的Flash端时序波形图,我们知道了FlexSPI的Prefetch功能确实在一定程度上改善了Flash访问效率,但是AHBRXBuffer最大仅1KB(对而言),不可拆分成更小粒度Buffer去缓存不同Flash地址处的数据(对于同一AHBmaster而言),这样对于代码中多个不同小数据块重复的Flash空间访问,Prefetch机制并没有明显提升访问效率。
针对这种不连续Flash地址空间频繁访问低效情况,ARMCortex-M7内核给出了解决方案,那就是L1Cache技术,今天痞子衡就来继续测一测开启L1Cache下的FlashAHB读访问情形(本文主要针对D-Cache):
一、Cortex-M7的Cache功能
对于Cortex-M系列家族(M0+/M3/M4/M7/M23/M33/M35P/M55)来说,L1Cache仅在Cortex-M7和Cortex-M55内核上存在,说白了,L1Cache是专为高性能内核配置的,而目前的系列微控制器都是基于Cortex-M7内核。
下面是的内核系统框图,可以看到它集成了32KBD-Cache,Cache经由AXI64总线连到SIM_M7和SIM_EMS模块,最终转成AHB总线连接到FlexSPI模块,因此对于Flash的AHB读访问是可以受到D-Cache加速的。

关于D-Cache工作机制,可以在ARMCortex-M7ProcessorTechnicalReferenceManual手册中找到详细解释。简单地概括就是32KBD-Cache会被划分成1024个CacheLine,每个CacheLine大小为32个字节,四个CacheLine是一组(即所谓的4-waysetassociative),每一组CacheLine会有一个地址标签,地址标签用来记录Cache所缓存的数据所在目标地址信息。
L1D-Cache使能时,对目标存储器的AHB读访问总共有两大类:Hit(要访问的数据在Cache里面)、Miss(要访问的数据不在Cache里面),Hit没什么好说的,直接从Cache里取数据就行了;Miss后则会先把数据从目标存储器中读到Cache里,然后再从Cache读出数据(这就是所谓的Read-Allocate,实际上有另一个名词Read-Through与之对应,Read-Through即直接从目标存储器中读出数据,一般是Cache不使能时的行为)。
对目标地址空间的Cache策略控制主要是属性配置(在内核MPU模块里)和开关控制(在内核SCB模块里),下面BOARD_ConfigMPU()函数即是典型的对FlexSPI地址映射空间所分配的Flash区域的Cache属性配置,这个代码里将0x60000000开始的64MB空间属性配成了NormalMemory,不共享,Cache使能并且写访问行为是Write-Back(写访问还有另一种策略Write-Through),读访问行为不用配置(固定Read-Allocate)。
/*MPUconfiguration.*/voidBOARD_ConfigMPU(void){/*DisableIcacheandDcache*/SCB_DisableICache();SCB_DisableDCache();/*DisableMPU*/ARM_MPU_Disable();/*Region0setting:Instructionaccessdisabled,Nodataaccesspermission.*/MPU-RBAR=ARM_MPU_RBAR(0,0x00000000U);MPU-RASR=ARM_MPU_RASR(1,ARM_MPU_AP_NONE,2,0,0,0,0,ARM_MPU_REGION_SIZE_4GB);/*Region2setting:MemorywithDevicetype,notshareable,non-cacheable.*/MPU-RBAR=ARM_MPU_RBAR(2,0x60000000U);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,2,0,0,0,0,ARM_MPU_REGION_SIZE_512MB);if/*EnableMPU*/ARM_MPU_Enable(MPU_CTRL_PRIVDEFENA_Msk);/*EnableIcacheandDcache*/SCB_EnableDCache();SCB_EnableICache();}最后再提一下跟本文主题不相干的Cache使能下写访问行为策略:
二、D-Cache实验准备
参考文章《实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形(无缓存)》里的第一小节实验准备,本次实验需要做一样的准备工作。
三、D-Cache实验代码
参考文章《实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形(无缓存)》里的第二小节实验代码,本次实验代码关于工程和链接文件方面是一样的设置,但是具体测试函数改成如下ramfunc型函数test_cacheable_read()。关于D-Cache这次会有很多种不同测试,while(1)语句前的系统配置保持不变,while(1)里面的语句可根据实际测试情况去调整:
pragmaoptimize=none__ramfuncdefineAHB_ADDR_START(0x60002400)voidtest_cacheable_read(void){//略去系统配置(I-Cache、Prefetch关闭,D-Cache开启)while(1){SDK_DelayAtLeastUs(10,SystemCoreClock);for(uint32_ti=1;i=8;i++){SDK_DelayAtLeastUs(2,SystemCoreClock);memcpy((void*)0x20200000,(void*)AHB_ADDR_START,i);}}}4.1.1AHB_ADDR_START取值[0x60002400-0x60002418]
当AHB_ADDR_START取值范围在[0x60002400-0x60002418]中时,Flash端的时序波形图都是如下同一个。因为有了D-Cache,现在我们看不到周期性的CS信号了,说明除了Flash新地址访问是必须要通过FlexSPI外设去读取Flash之外,其后的同一Flash地址的重复访问都直接发生在D-Cache里了。
另外D-Cache起始缓存地址永远是32字节对齐的地址处,并且一次缓存32byte的数据(因为D-CacheLine大小就是32byte),所以波形结果里看,起始地址都是0x60002400,一次读取32byte数据(存在一个D-CacheLine里),因此之前不开D-Cache和Prefetch下的AHBBurstRead策略导致的访问不同对齐地址的波形差异测试结果在这里就不存在了。
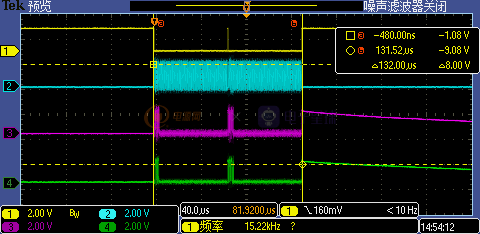
4.1.2AHB_ADDR_START=0x60002419
当实际代码中要读取的Flash数据会横跨两个相邻32字节对齐的数据块(0x60002400-0x6000241f,0x60002420-0x6000243f),此时Flash端会出现两次CS有效信号,每次均传输32byte数据,D-Cache一直在持续作用,这次动用了两个D-CacheLine(D-Cache总大小有32KB,共有1024个CacheLine),因此在Flash端我们还是看不到周期性CS信号。
4.1.3追加实验,从0x60002400处读取1KB
当代码循环读取1KB数据时,波形图上可以看到32个CS有效信号,每个CS有效期间传输32byte数据,总计1KB数据的传输,D-Cache这次派出了32个CacheLine,在Flash端我们依然看不到周期性CS信号。
4.2重做有预取一文中的实验
现在让我们在开启D-Cache的情况下重新做文章《实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形(有预取)》中全部实验:
4.2.1循环读取首地址32字节对齐的1KB空间内的任意长度数据块,起始拷贝地址位于前31个字节内
这种情况下,Flash端实际波形与《实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形(有预取)》中4.1里的测试结果差不多,这里就不再贴图了。Prefetch机制做第一层缓存,D-Cache获取PrefetchBuffer里的结果做二次缓存,唯一的差异是因为D-Cache的存在,缓存起始地址可能会发生变化(从八字节对齐变成了32字节对齐):
definePREFETCH_TEST_START(0x60002400+PREFETCH_TEST_ALIGNMENT)uint32_ttestLen=0x1;//可取值1-(1KB-PREFETCH_TEST_ALIGNMENT)voidtest_cacheable_read(void){//略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)while(1){memcpy((void*)0x20200000,(void*)PREFETCH_TEST_START,testLen);}}4.2.2循环读取大于1KB的数据块或首地址非32字节对齐的1KB数据块
这种情况下,Flash端会有两次完整的1KBPrefetch操作,第一次Prefetch操作读取了0x60002400处的1KB,第二次Prefetch操作读取了0x60002800处的1KB。因为有D-Cache的存在,第二次Prefetch操作有了足够时间去完成,不用额外插入软延时去避免其被while(1)循环回来的下一次访问需求打断了:
voidtest_cacheable_read(void){//略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)while(1){memcpy((void*)0x20200001,(void*)0x60002401,0x400);}}4.2.3循环读取两个不同数据块(在首地址32字节对齐的两个不同1KB空间内)
这种情况下,即使有D-Cache存在,第一次CS期间的Prefetch操作(即memcpy((void*)0x20200000,(void*)0x60002400,0x100);引发的)还是被第二次CS的Prefetch操作打断了(即memcpy((void*)0x20200400,(void*)0x60002800,0x100);),但是第二次CS期间的Prefetch操作不会再被打断,因为接下来while(1)循环回来的Flash数据访问需求已经缓存在D-Cache里:
voidtest_cacheable_read(void){//略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)while(1){memcpy((void*)0x20200000,(void*)0x60002400,0x100);memcpy((void*)0x20200400,(void*)0x60002800,0x100);}}4.3如何在D-Cache使能的情况下看到周期性CS信号
前面测试了那么多种情况,我们有没有可能在Flash端看到周期性CS信号呢,即Flash持续地被读取呢?当然可以,我们知道D-Cache总大小是32KB,我们只要循环拷贝32KB以上数据,D-Cache就开始hold不住了,这不,下面代码就能让我们看到久违的周期时序波形图了(小心,Flash持续工作会多耗电的,哈哈)。
voidtest_cacheable_read(void){//略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)while(1){memcpy((void*)0x20200000,(void*)0x60002400,0x8000+1);}}至此,实抓Flash信号波形来看的FlexSPI外设下AHB读访问情形痞子衡便介绍完毕了,掌声在哪里~~~
查看原文:
SiCMOSFET用于电机驱动的优势在哪里在我们的传统印象中,电机驱动系统往往采用IGBT作为开关器件,而SiCMOSFET作为高速器件往往与光伏和电动汽车充电等需要高频变换的应用相关联。但在特定的电机应用中,SiC仍然具有不可比拟的优势,他们是:
1低电感电机
低电感电机有许多不同应用,包括大气隙电机、无槽电机和低泄露感应电机。它们也可被用在使用PCB定子而非绕组定子的新电机类型中。这些电机需要高开关频率(50-100kHz)来维持所需的纹波电流。然而,对于50kHz以上的调制频率使用绝缘栅双极晶体管(IGBT)无法满足这些需求,如果是380V系统,硅MOSFET耐压又不够,这就为宽禁带器件开创了新的机会。
2高速电机
由于拥有高基波频率,这些电机也需要高开关频率。它们适用于高功率密度电动汽车、高极数电机、拥有高扭矩密度的高速电机以及兆瓦级高速电机等应用。同样,IGBT能够达到的最高开关频率受到限制,而通过使用宽禁带开关器件可能能够突破这些限制。例如燃料电池中的空压机。空压机最高转速超过15万rpm,空压机电机控制器的输出频率超过2500Hz,功率器件需要很高的开关频率(超过50kHz),因此SiC-MOSFET是这类应用的首选器件。
3恶劣工况
传统的电机驱动中,往往使用IGBT作为开关器件。那么,SiCMOSFET相对于SiIGBT有哪些优势,使得它更适合电机驱动应用?
首先,从开关特性角度看,功率器件开关损耗分为开通损耗和关断损耗。
关断损耗
IGBT是双极性器件,导通时电子和空穴共同参与导电,但关断时由于空穴,只能通过复合逐渐消失,从而产生拖尾电流,拖尾电流是造成IGBT关断损耗的大的主要原因。SiCMOSFET是单极性器件,只有电子参与导电,关断时没有拖尾电流使得SiCMOSFET关断损耗大大低于IGBT。
开通损耗
IGBT开通瞬间电流往往会有过冲,这是反并联二极管换流时产生的反向恢复电流。反向恢复电流叠加在IGBT开通电流上,增加了器件的开通损耗。IGBT的反并联二极管往往是SiPiN二极管,反向恢复电流比较明显。而SiCMOSFET的结构里天然集成了一个体二极管,无需额外并联二极管。SiC体二极管参与换流,它的反向恢复电流要远低于IGBT反并联的硅PiN二极管,因此,即使在同样的dv/dt条件下,SiCMOSFET的开通损耗也低于IGBT。另外,SiCMOSFET可以使得伺服驱动器与电机集成在一起,从而摒除线缆上dv/dt的限制,高dV/dt条件下,SiC的开关损耗会进一步降低,远低于IGBT。即使是开关过程较慢时,碳化硅的开关损耗也优于IGBT。
此外,SiCMOSFET的开关损耗基本不受温度影响,而IGBT的开关损耗随温度上升而明显增加。因此高温下SiCMOSFET的损耗更具优势。
再考虑dv/dt的限制,相同dv/dt条件下,高温下SiCMOSFET总开关损耗会有50%~60%的降低,如果不限制dv/dt,SiC开关总损耗最高降低90%。
从导通特性角度看:
SiCMOSFET导通时没有拐点,很小的VDS电压就能让SiCMOSFET导通,因此在小电流条件下,SiCMOSFET的导通电压远小于IGBT。大电流时IGBT导通损耗更低,这是由于随着器件压降上升,双极性器件IGBT开始导通,由于电导调制效应,电子注入激发更多的空穴,电流迅速上升,输出特性的斜率更陡。对应电机工况,在轻载条件下,SiCMOSFET具有更低的导通损耗。重载或加速条件下,SiCMOSFET导通损耗的优势会有所降低。
CoolSiC™MOSFET在各种工况下导通损耗降低,
下面通过一个实例研究,实际验证SiCMOSFET在电机驱动中的优势。
假定以下工况,对比三款器件:
IGBTIKW40N120H3,
SiCMOSFETIMW120R060M1H和IMW120R030M1H。
测试条件
Vdc=600V,VN,out=400V,IN,out=5A–25A,
fN,sin-out=50Hz,fsw=4-16kHz,Tamb=25°C,
cos(φ)N=0.9,Rth,HA=0.63K/W,dv/dt=5V/ns
M=1,Vdc=600V,fsin=50Hz,RG@dv/dt=5V/ns,fsw=8kHz,线缆长度5m,Tamb=25°C
可以看出,基于以上工况,同样的温度条件下,30mohm的器件输出电流比40AIGBT提高了10A,哪怕换成小一档的60mohmSiCMOSFET,输出电流也能提升约5A。而相同电流条件下,SiCMOSFT的温度明显降低。
综上所述,SiC开关器件能为电机驱动系统带来的益处总结如下:
更低损耗‒降低耗电量,让人们的生活更加环保、可持续。
性能卓越‒实现更高功率密度,通过以更小的器件达到相同性能,来实现更经济的电机设计。
结构紧凑‒实现更紧凑、更省空间的电机设计,减少材料消耗,降低散热需求。
更高质量‒SiC逆变器拥有更长使用寿命,且不易出故障,使得制造商能够提供更长的保修期。
最后,英飞凌CoolSiC™能保证单管3us,Easy模块2us的短路能力,进一步保证系统的安全性与可靠性。
查看原文:
换个角度学习逆变器(2)--SPWM方波傅里叶分析接上文学习逆变器就要搞清楚的第三个问题:LC滤波器能滤除什么样的波?
问题3
根据SPWM正弦波的傅里叶变换公式可知,SPWM方波和Sin正弦波之间的的差别就是,SWPM方波内存在其余频率的谐波,因此为了输出标准的正弦波,LC滤波器就必须把谐波滤除。进步分析SPWM的谐波是什么,就可以确定LC滤波器的性能,进而确定滤波器的参数。
SPWM方波谐波的定量分析
现有对SPWM双极性的谐波分析结论如下:
1基波分量的幅值如下:m*Ud,其中m为调制比,Ud为直流侧电压。
2高频谐波的幅值公式如下:
谐波对应的频率为
即主要的谐波频率都在载波频率倍数及其附近的频率处。
3幅值最大的谐波频率为分量为谐波频率,最大幅值为
本文主要通过仿真进行FFT变换分析PWM波的谐波含量,通过matlab程序将谐波与基波重组并对比仿真中输出的双极性SPWM方波。首先利用simulink对SPWM进行仿真,仿真参数如下:输入电压500V,载波频率5Khz,调制波频率50Hz,仿真步长1e-6,载波比0.8,双极性调制,得到SPWM方波的谐波含量分析。仿真模型如下:
分析结果如下:
设置FFT变换的展示类型为list(relativetospecifiedbase),已表格的形式输出结果,且结果为实际的电压值。设置的最大分析频率为100Khz,得到的FFT结果如下:
分析步骤如下:
1FFT数据谐波中的幅值较大的谐波提取出来
2将提取出来的谐波进行重组。
3将重组的波形与FFT分析前的波形进行对比。
1程序将幅值大于20V的谐波进行提取得到如下数组:
已知仿真中直流侧输入电压500V,调制比为0.8.因此基波的幅值含量为400V。通过程序采集到的基波分量为398V,其余分量均为谐波分量,谐波分分量主要包含在5KHz左右、10KHz左右、15KHZ左右。上述分析均满足FFT分析的计算公式。将采集到的波形进行合成,合成的波形如下:
该波形已经可以看出来是个方波,下面与PWM波进行对比得到如下对比图。
可以看到合成的方波与实际的方波对比,还存在的一些高频的分量,出现误差的原因就是,FFT分析时最大的频率为100Khz,再高频率的谐波有考虑到,且仅提取了大于20V的谐波。通过上述的程序分析,就可以定量的分析出,SPWM方波内含与载波频率呈倍数的谐波含量,主要通过合理的滤波将高频谐波滤除就可以得到理想的正弦波输出电压。
仿真模型及程序放在附件,需要的自取。
程序如下:
l=length();
Data=struct('mag',{},'phase',{},'freq',{});
pmax=length(tout);%%仿真输出波形的点数
Pout=zeros(pmax,1);%%正弦波输出波形存储数组
tstep=1e-6;%%仿真步长
%%从FFT数据中提取谐波含量较大的谐波
Magmax=20;%%对大于Magmax的谐波进行提取
k=1;%%提取谐波的个数+1
fori=1:1:l
if((i,1)Magmax)
Data(k).mag=(i,1);
Data(k).phase=(i,1);
Data(k).freq=(i,1);
forj=1:1:pmax
Data(k).sin(j)=Data(k).mag*sind(2*180*Data(k).freq*tout(j,1)+Data(k).phase);
k=k+1;
%%正弦波的合成
nmax=k-1;%%正弦波输出波形迭代的次数k-1,最大值为k-1
fori=1:nmax
Pout=Pout+(Data(i).sin)';
%%输出波形
tmax=0.02;%%输出波形的时间
figure(1)
plot(tout(1:tmax/tstep),Pout(1:tmax/tstep))
holdon
plot(PWM(1:tmax/tstep,1),PWM(1:tmax/tstep,2))
查看原文:
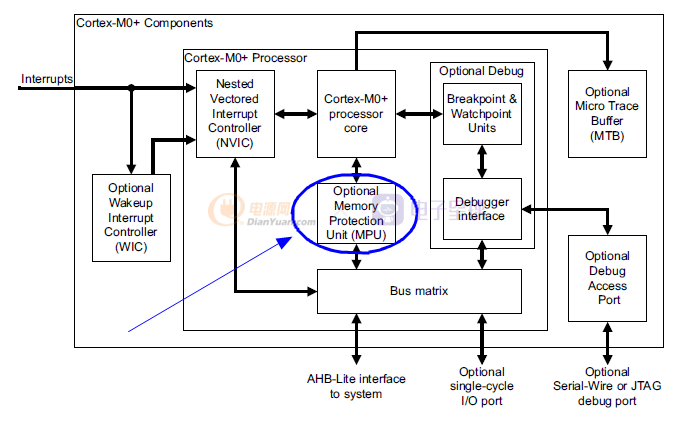
Cortex-M内核存储保护单元MPU大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是ARMCortex-M存储保护模块(MPU)。
《ARMCortex-M内核MCU开发那些事》的内核篇连载最早是2017年底开始写的,但只写了7篇就停更了,鸽了这么久实在不好意思。最近在支持客户的过程中,发现客户对Cortex-M的MPU功能不太了解,导致项目中出了内存非法访问的问题,借此机会,痞子衡将重启这个Cortex-M内核篇连载,为大家系统地讲解下MPU:
一、MPU是什么?
MPU全称"MemoryProtectionUnit",中文叫“存储保护单元”,它是Cortex-M处理器内部的一个模块(注意:并不是所有Cortex-M版本都支持MPU,并且在一些支持MPU的Cortex-M版本上,MPU也是可选组件(要看具体MCU厂商是否实现))。
让我们结合如下Cortex-M处理器(以CM0+为例,其他版本类似)模块框图中来解释MPU作用,从框图中大家可以看到,MPU介于Core和Busmatrix中间。Busmatirx是ARM系统总线大管家,用以实现系统内多主(Core,DMA等)、多从(内部RAM,APB外设,外部总线等)的交联和仲裁,Core通过Busmatirx可以访问到系统空间内的所有存储/外设资源,现在MPU挡在了Core和Busmatirx中间,这意味着从此Core对系统存储资源的访问需要经过MPU的权限控制与审核。
二、存储空间类型与属性
MPU对存储空间的访问权限控制主要包含:Strongly-ordered(是否严格有序)、Shareable(是否共享)、Cacheable(是否缓存)、ExecuteNever(是否可执行)等方面,不同的访问权限配置造就了系统里不同的存储空间类型与属性,这一切都是为了能够让存储资源被Core高效且可靠地访问(RTOS环境下比裸机程序下更需要可靠保证)。
Shareable/Cacheable/ExecuteNever属性大家应该都了解,有必要特别提一下Strongly-ordered属性,因为不同属性的存储空间配置会给代码执行时内存访问指令的顺序方面造成了困扰,比如两个内存访问指令A1,A2,假定它们是同一主设备接口发出的,并且A1在程序代码里出现在A2之前,根据A1/A2不同的属性组合其实际执行结果如下,有些时候系统无法保证A1操作一定比A2操作先完成,这时候需要软件设计里手工插入内存屏障指令(ISB,DSB)来保证最终顺序。
如果MPU模块不存在或者没有被使能,处理器系统4GB存储空间默认的属性如下(表中XN即ExecuteNever;WT即Write-Throug;WBWA即Write-Back,writeallocate):
三、MPU功能配置
MPU模块是处理器内核自带的模块,其寄存器定义见\CMSIS\Include\core_cm0plus/3/4/7.h文件,具体寄存器功能解释这里就不展开了,可翻阅对应ARMv6/7-MArchitectureRM或者Cortex-M0+/3/4/7GenericUG手册找到具体解释。
简单概括一下,MPU最多支持8/16个主空间划分(MPU_RNR[REGION],REGION取值0-7或者0-15),每个主空间可以自由设置其属性(MPU_RASR[XN/AP/TEX/S/C/B]),空间大小是可设的,最小粒度为32bytes,空间之间也可以重叠(高序号空间属性会覆盖低序号空间属性)。当某个主空间分配的大小超过256bytes时,这个主空间还可以被等分成8个子空间,每个子空间有独立的开关控制(MPU_RASR[SRD])。
MPU模块最核心的寄存器是MPU_RASR,其提供了存储空间具体访问权限配置,XN/AP/TEX/S/C/B位域共同决定了最终权限,用户可根据项目实际需求进行配置。
上表中关于Cache策略的设置AA/BB定义如下:00Non-cacheable01Write-back,writeandreadallocate10Write-through,nowriteallocate11Write-back,nowriteallocate
四、MPU配置代码示例
ARM官方为MPU模块预实现了一些功能函数/宏定义,见\CMSIS\Include\mpu_armv6/7.h文件,其中最常用的是ARM_MPU_RBAR和ARM_MPU_RASR宏。
如下是恩智浦的MPU示例配置代码,这是颗Cortex-M7内核的MCU,内部有2MBRAM,官方MIMXRT1170-EVK板卡为其外挂了16MB的NORFlash和64MB的SDRAM。
代码中Region2/3/4/5/6/8/9是实际用户存储空间的配置,其他Region0/1/7是基本系统空间的配置,未定义空间的非法访问会产生MemManage或者BusFault。
voidBOARD_ConfigMPU(void){/*DisableIcacheandDcache*/SCB_DisableICache();SCB_DisableDCache();/*DisableMPU*/ARM_MPU_Disable();////////////////////////////////////////////////////////////////////////////////////////系统全部4GB空间先配置成XN属性的Device/*Region0setting:Instructionaccessdisabled,Nodataaccesspermission.*/MPU-RBAR=ARM_MPU_RBAR(0,0x00000000U);MPU-RASR=ARM_MPU_RASR(1,ARM_MPU_AP_NONE,2,0,0,0,0,ARM_MPU_REGION_SIZE_4GB);////////////////////////////////////////////////////////////////////////////////////////0x00000000之后的1GB空间配置成非XN属性的Device/*Region1setting:MemorywithDevicetype,notshareable,non-cacheable.*/MPU-RBAR=ARM_MPU_RBAR(1,0x00000000U);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,2,0,0,0,0,ARM_MPU_REGION_SIZE_1GB);////////////////////////////////////////////////////////////////////////////////////////0x00000000之后的内部RAM空间配置(实际2MB)/*Region2setting:MemorywithNormaltype,notshareable,outer/innerwriteback*/MPU-RBAR=ARM_MPU_RBAR(2,0x00000000U);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,0,0,1,1,0,ARM_MPU_REGION_SIZE_256KB);/*Region3setting:MemorywithNormaltype,notshareable,outer/innerwriteback*/MPU-RBAR=ARM_MPU_RBAR(3,0x20000000U);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,0,0,1,1,0,ARM_MPU_REGION_SIZE_256KB);/*Region4setting:MemorywithNormaltype,notshareable,outer/innerwriteback*/MPU-RBAR=ARM_MPU_RBAR(4,0x20200000U);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,0,0,1,1,0,ARM_MPU_REGION_SIZE_1MB);/*Region5setting:MemorywithNormaltype,notshareable,outer/innerwriteback*/MPU-RBAR=ARM_MPU_RBAR(5,0x20300000U);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,0,0,1,1,0,ARM_MPU_REGION_SIZE_512KB);////////////////////////////////////////////////////////////////////////////////////////0x30000000之后的外部NORFlash空间配置(实际16MB)if////////////////////////////////////////////////////////////////////////////////////////0x80000000之后的外部SDRAM空间配置(最大512MB,实际64MB)/*Region7setting:MemorywithDevicetype,notshareable,non-cacheable.*/MPU-RBAR=ARM_MPU_RBAR(7,0x80000000U);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,2,0,0,0,0,ARM_MPU_REGION_SIZE_512MB);ififvolatileuint32_ti=0;while((sizei)0x1U){i++;}if(i!=0){/*TheMPUregionsizeshouldbe2^N,5=N=32,regionbaseshouldbemultiplesofsize.*/assert(!(nonCacheStart%size));assert(size==(uint32_t)(1i));assert(i=5);/*Region9setting:MemorywithNormaltype,notshareable,non-cacheable*/MPU-RBAR=ARM_MPU_RBAR(9,nonCacheStart);MPU-RASR=ARM_MPU_RASR(0,ARM_MPU_AP_FULL,1,0,0,0,0,i-1);}/*EnableMPU*/ARM_MPU_Enable(MPU_CTRL_PRIVDEFENA_Msk);/*EnableIcacheandDcache*/SCB_EnableDCache();SCB_EnableICache();}附录一、MPU特性差异
至此,ARMCortex-M存储保护模块(MPU)痞子衡便介绍完毕了,掌声在哪里~~~
查看原文:
感应加热原理与IGBT应用拓扑分析(上)经常遇到很多同事和朋友问:为什么电磁炉和电饭煲要用到IGBT,这种应用的IGBT需要有什么特点?今天我们就给大家详细解释感应加热的原理和感应加热的拓扑分析。
在理解电磁感应加热的原理之前,先问自己一个问题,假如这个世界上没有电磁炉,你要烧开一锅水,会怎么做?
最常见的方式,就是点燃炉灶,把锅架在火上。
图1.传统燃气加热
然而这种方法是间接的加热方式,先由热源加热锅具,再通过锅具将热量传导到锅内的食物,在这一系列的过程中,必然会产生能量的损失。
所以,有没有一个办法,把锅具本身变成一个热源,让锅来直接煮水?
这,就要用到感应加热了。
感应加热的原理,如图2所示:
1.控制板通过谐振转换电路产生高频交流电流流经铜线圈;
2.在工作线圈上产生感应的磁场,感应磁场在金属锅具底部产生涡流;
3.涡流通过金属的趋肤效应让其电阻产生焦耳热,同时与材料的渗透性有关的磁滞损失也产生热量。
图2.涡流效应
等效电路如下图所示:
图3.等效电路
感应加热速度有以下特点:
1.烹饪容器底部的涡流与流经感应线圈的电流大小成正比,意味着增加感应线圈的电流会导致涡流的增加;烹饪容器的加热时间会更快。
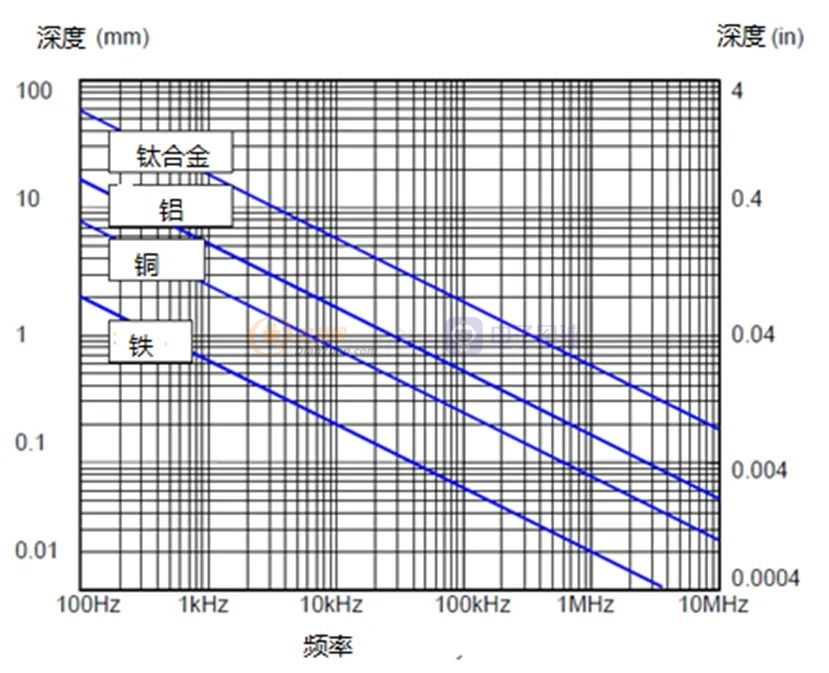
2.更高的频率将使涡流密度集中在更接近表面的地方,这反过来又会大大减少活性电流流的横截面积,从而间接增加电阻,增加加热效率,所以增加工作频率也会加快加热容器的速度。
所以感应加热需要谐振控制器在线圈上产生交变电流,并且为了达到一定功率,谐振控制器的电流及开关频率都要求比较高,那么开关器件势必要选用即能导通大电流又能快速开关的IGBT。
图4.频率对材料的标准穿透深度的影响
感应加热目前主流的拓扑有单端谐振和半桥谐振两种不同的拓扑,下图对两种拓扑特点做了详细的比较:
图5.感应加热应用范围和谐振拓扑的特点
1.单端谐振相对来讲控制简单,整体成本有优势;
2.如下图所示单端谐振不足之处就是功率范围明显受到制约,小功率(600W)会有硬开通产生大电流增加温升,大功率(2.3KW)单颗管子的温升很难控制;
图6.两种拓扑功率输出和温升的对应关系
下篇我们会结合拓扑的回路路径对两种拓扑的等效电路电流进行详细分析。
查看原文:
更多精彩内容,尽在电子星球APP()
六篇技术文章,让你秒懂电容的脾气秉性
七篇DIY技术文章献给你,让你脑洞全开
五篇文章帮你开启DSP的学习思路
汇总篇:关于PID知识,重点在此
很赞哦!(189)